





Numpy
数组(Numpy.ndarray)
numpy.array创建数组(Ndarray)
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
参数说明:
| 参数 | 说明 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
-
数组(Ndarray)的属性
size元素个数shape数组的形状,为元组类型ndim数组的维数,几层嵌套dtype数组的元素类型itemsize每个元素的字节大小
-
numpy.arange(start[, end])创建从start=0到end-1的元素的数组(Ndarray)
-
numpy.linspace(start, end, num, endpoint)start到end(默认包含,endpoint设为False则不包含)之间等分num份的数组
-
numpy.logspace(start, end, num, endpoint, base)start到end(默认包含,endpoint设为False则不包含)之间以base(默认为10,可修改base)等比的num个数组
-
numpy.zeros(shape)创建shpae(元组)类型的全0的数组
-
numpy.eye(fact)创建fact阶的二维单位矩阵
-
numpy.diag(list)创建一维list为对角线元素的对角矩阵
-
numpy.ones(shape)创建形状为shape的全1数组
-
ndarray.ravel()将数组所有横向展开
-
ndarray.flatten(order="C")将数组所有横向展开(order==‘C’),纵向展开(order=“F”)
-
numpy.hstack((arr1,arr2))将两个数组横向合并
-
numpy.vstack((arr1,arr2))将两个数组纵向组合
-
numpy.concatenate((arr1,arr2),axis=1)将两个数组横向(axis1), 纵向(axis0)合并
-
numpy.hsplit(arr)将两个数组横向拆分
-
numpy.vsplit(arr)将两个数组纵向拆分
-
numpy.split(arr,axis=1)将两个数组横向(axis1), 纵向(axis0)拆分
随机数(Numpy.random)
-
numpy.random.random(size=(int||shape))生成无约束的([0, 1))之间的随机数,size可放为shape
-
numpy.random.rand(int,int,,,,)生成[0,1)之间的随机数,参数为维数
-
numpy.rando.randn(int,int,,,,)生成之间的标准正态分布随机数,参数为维数
-
numpy.random.randint(low, hight, size)生成[low,high)之间的整数
-
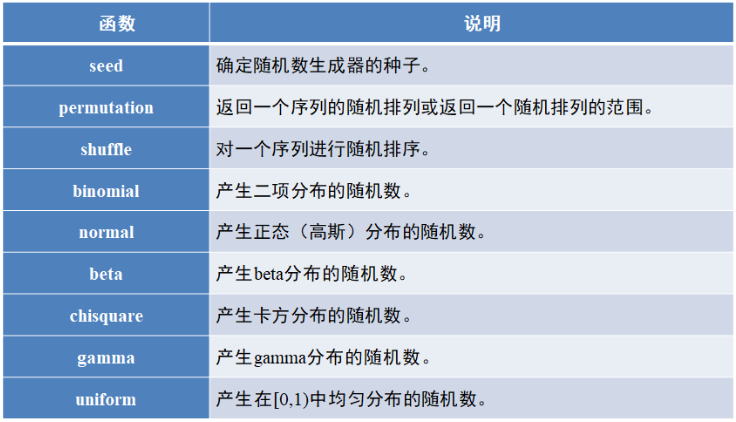
random模块生成函数
矩阵(Numpy.matrix)
-
numpy.mat([[1, 2, 3], [4, 5, 6]])创建矩阵
-
numpy.bmat("a b;b a")组合矩阵
-
numpy.mutiply(arr1,arr2)矩阵对应位置相乘
-
矩阵运算符
| 运算符 | 说明 |
|---|---|
| matrix*3 | 每个元素乘3 |
| matrix1±matrix2 | 矩阵对应位置相加减 |
| matrix*matrix | 矩阵乘法 |
- 矩阵属性
| 属性 | 说明 |
|---|---|
| T | 返回矩阵的转置 |
| H | 返回矩阵的共轭转置 |
| I | 返回逆矩阵(必须满足原矩阵行列式不为0,即为存在可逆矩阵,否则报错) |
| A | 返回2维矩阵的视图 |
矩阵和数组的异同
-
同
-
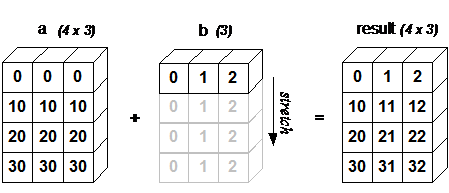
广播机制
当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。
下面的图片展示了数组 b 如何通过广播来与数组 a 兼容。
-
部分基本运算符的功能一致(+,-)
-
-
异
- 矩阵相乘即为数学上的矩阵相乘,而数组相乘为对应位置的元素相乘
- 矩阵想实现对应位置元素相乘使用
numpy.mutiply(arr1,arr2),而数组可以直接相乘
文件读写
-
save函数是以二进制的格式保存数据。 np.save("…/tmp/save_arr",arr)
-
load函数是从二进制的文件中读取数据。 np.load("…/tmp/save_arr.npy")
-
savez函数可以将多个数组保存到一个文件中。 np.savez(’…/tmp/savez_arr’,arr1,arr2),存为.npz二进制文件
-
注意:存储时可以省略扩展名,但读取时不能省略扩展名。
-
savetxt函数是将数组写到某种分隔符隔开的文本文件中。
np.savetxt("…/tmp/arr.txt", arr, fmt="%d", delimiter=",")
-
loadtxt函数执行的是把文件加载到一个二维数组中
np.loadtxt("…/tmp/arr.txt",delimiter=",")
-
genfromtxt函数面向的是结构化数组和缺失数据。
np.genfromtxt("…/tmp/arr.txt", delimiter = “,”)
简单数据分析
-
排序
ndarray.sort(a,axis,kind,order)将数组升序排序- a: 要排序的数组
- axis: 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序, axis=0 按列排序,axis=1 按行排序
- kind: 默认为’quicksort’(快速排序)
- order: 如果数组包含字段,则是要排序的字段
ndarray.argsort()函数返回值为重新排序值的下标numpy.lexsort(tuple)用于对多个序列进行排序,根据最后一个传入数据排序的
-
重复
-
numpy.repeat(arr,num,axis)arr数组的每个元素在纵向(默认axis=1)重复num次或者横向(axis=0) -
numpy.tile(arr,num)arr数组的所有元素横向复制一次a = np.array([2, 48, -5, 9, 5, 3, 10, 6]) print(a.reshape(2, 4)) c = np.tile(a.reshape(2, 4), 3) print(c) #结果 #[[-5 2 3 5] # [ 6 9 10 48]] #[[-5 2 3 5 -5 2 3 5 -5 2 3 5] # [ 6 9 10 48 6 9 10 48 6 9 10 48]] -
numpy.unique(arr,num)返回去重复并排序后的一维数组(当num>=可返回二维数组,数组一为去重排序的数组,数组二维去重排序后的元素在原数组中的下标)
-
Matplotlib
绘图
-
plt.figure(figsize=shape, dpi)创建画布
-
plt.plot(x, y)图像绘制
-
plt.savefig("../data/test.png")图像保存
-
plt.show()图像显示
-
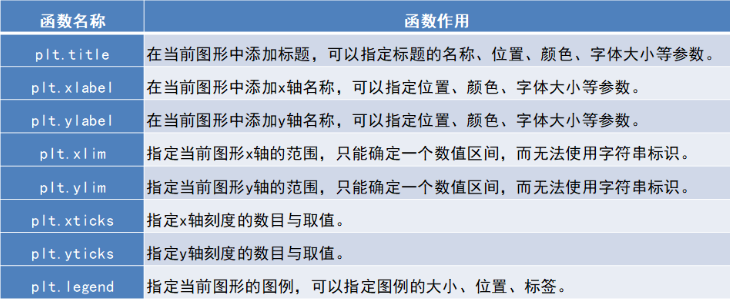
其它函数
-
实例
import matplotlib.pyplot as plt # 1.创建画布 plt.figure() # plt.figure(figsize=(20, 8), dpi=100) # 2.图像绘制 x = [1, 2, 3, 4, 5, 6] y = [3, 6, 3, 5, 3, 10] plt.plot(x, y) # 2.1图像保存, 必须在plt.show()之前完成,应为那个函数会释放内存 plt.savefig("../data/test.png") # 3.图像显示 plt.show()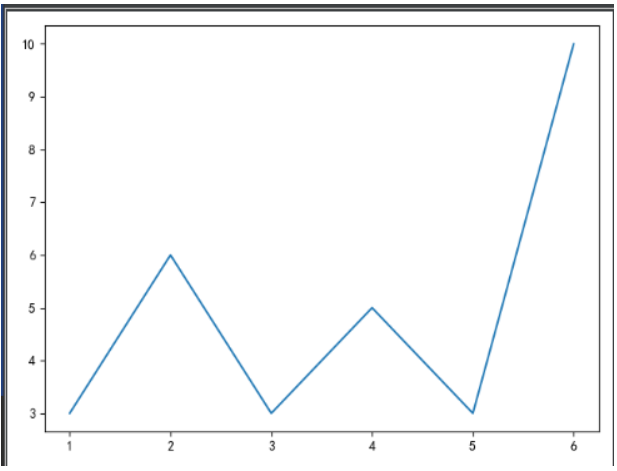
绘制散点图
-
plt.scatter(x, y, s=None, c=None, marker=None, alpha=None, **kwargs)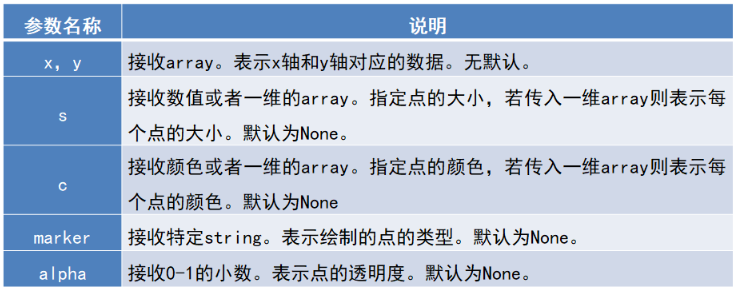
-
plt.plot(*args, **kwargs)*args代表x, y的坐标,可为数值或数组;
**kwargs代表控制曲线的格式字符串,由颜色字符、风格字符和标记字符等属性组成,同一种属性只能给一个值,属性间可随意组合。
绘制直方图
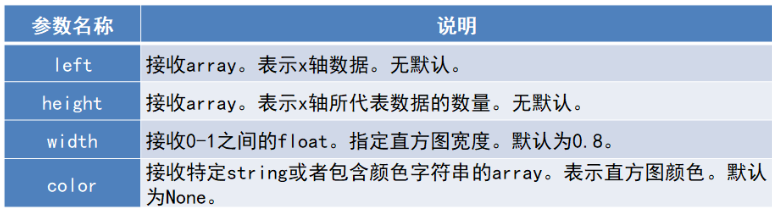
matplotlib.pyplot.bar(left,height,width = 0.8,bottom = None,hold = None,data = None, **kwargs)
绘制饼图
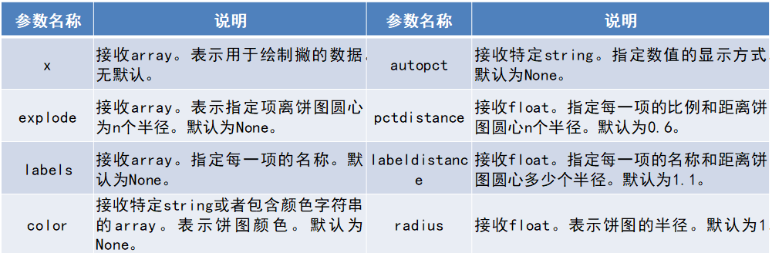
matplotlib.pyplot.pie(x, explode=None, labels=None, colors=None, autopct*=None,* pctdistance*=0.6, shadow=False,* labeldistance*=1.1,* startangle*=None, radius=None, … )*
箱线图
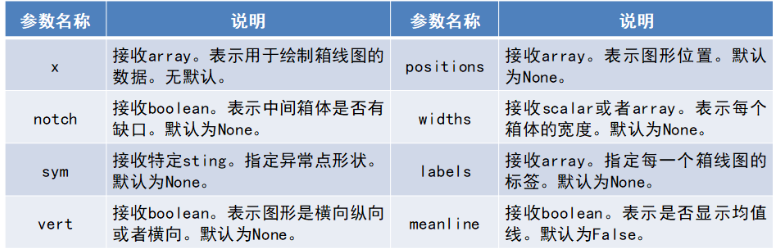
matplotlib.pyplot.boxplot(x, notch=None, sym*=None,* vert*=None,* whis*=None, positions=None, widths=None,* patch_artist*=None,meanline=None, labels=None, … )*
Pandas
数据库存取数据
-
读取
-
安装
sqlalchemy库 -
创建引擎
engine = create_engine("mysql+pymysql://root:xq4077@127.0.0.1:3306/test?charset=utf8") ''' 数据库产品名+连接工具名://用户名:密码@数据库IP地址:数据库端口号/数据库名称?charset = 数据库数据编码 ''' -
读取数据
- 读取整个表
data1 = pandas.read_sql_table("book", con=engine)- 查询语句
data2 = pandas.read_sql_query("select * from book", con=engine)- 综合查询(可查询,可读表)
data3 = pd.read_sql_query("select * from book", con=engine)
-
-
存入
data2.to_sql("book2", engine, if_exists='replace', index=False) # index=False则不会将行索引一起存入数据库
存取CSV文件
- 读取
data2 = pd.read_csv("../data/meal_order_info.csv", encoding="gbk")
# seq=',' 默认以","作为分隔符
- 存入
data2.to_csv("../data/temp1.csv", index=False)
存取其它任意格式数据
- 读取
data1 = pd.read_table("../data/meal_order_info.csv", encoding="gbk", sep=",")
#默认以"\t"分隔
- 存入
data1.to_csv("../data/temp1.csv", index=False)
存取Excel
- 需安装
xlrd库 - 读取
data = pd.read_excel("../data/meal_order_detail.xlsx", 0, 0)
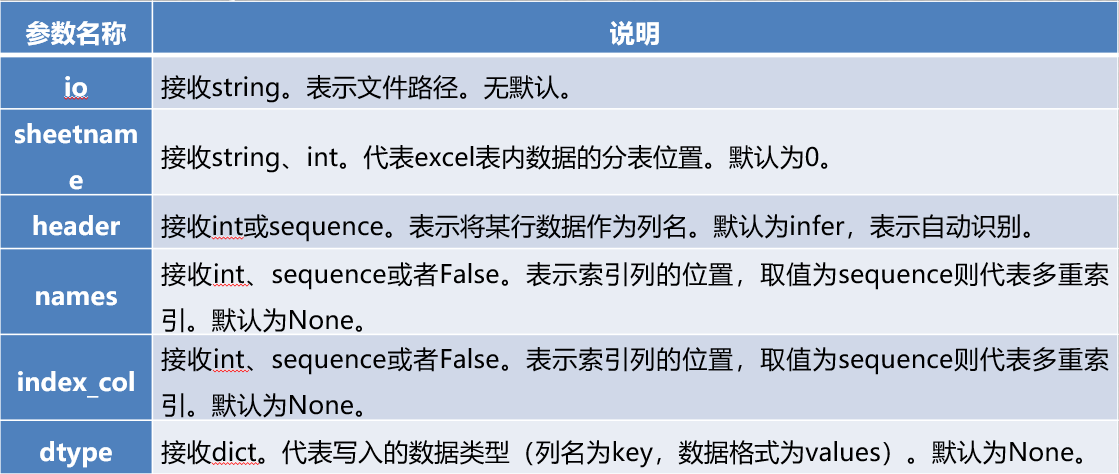
- 写入
# 写入
# data.to_excel("../data/temp2.xlsx", sheet_name="A")
# data.to_excel("../data/temp2.xlsx", sheet_name="B", index=False)
# 上述写法会覆盖掉已存在文件,不会增加表
# 正确写法
with pd.ExcelWriter("../data/temp2.xlsx") as w:
data.to_excel(w, sheet_name="A")
data.to_excel(w, sheet_name="B", index=False)
DataFrame
- 属性
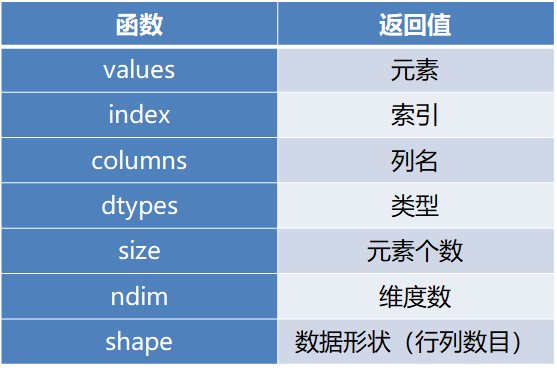
-
元素获取,索引
data['dishes_id'][:5] #列名为'dishes_id'的列的下标0-4的元素 print(data.iloc[2, 2]) #第3条数据的第3个字段值 print(data.loc[2, 'order_id']) #第3条数据的order_id字段值 # 'order_id'列中值等于417的所有数据行 data2 = data.loc[data['order_id'] == 417, :] # 'order_id'列中值等于417的所有数据行中的'detail_id'和'order_id'列组成# 的数据表 data2 = data.loc[data['order_id'] == 417, ['detail_id', 'order_id']] # 下标为2-10的行中的'detail_id'和'order_id'列组成的数据表 data.loc[2:10, ['detail_id', 'order_id']] # 前几行,后几行 data3 = data.head(5) data4 = data.taile(5) -
修改表
# 将'counts'列和'amounts'列相乘结果存入'total_price'列 data['total_price'] = data['counts'] * data['amounts'] # 删除列, inplace=True表示更改原数据,否则对data不生效返回的值为更改的结果 data.drop(labels='total_price', axis=1, inplace=True) # 或者 del data['total_price'] -
统计
# 求每列平均值 print(data.mean()) # 求每列最小值 print(data.min()) # 描述 print(data.describe())
-
频数统计
data['dishes_name'].value_counts()
时间处理
| 标题: | Python数据分析 |
|---|---|
| 链接: | https://www.fightingok.cn/detail/3 |
| 更新: | 2022-09-18 22:31:19 |
| 版权: | 本文采用 CC BY-NC-SA 3.0 CN 协议进行许可 |