一、张量基本术语
1.1 阶(Order)
张量的阶,即为张量的维度大小。
1.2 纤维(Fibers)
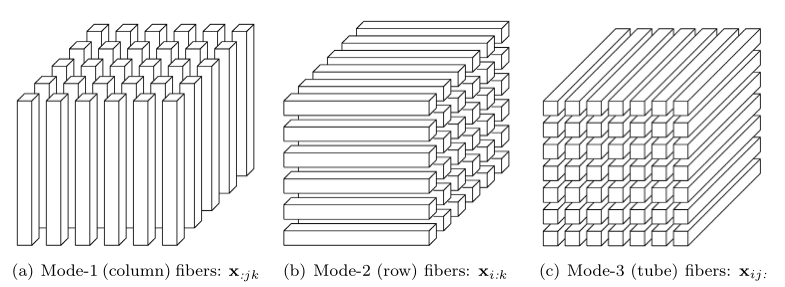
从张量中抽取出的一维向量,指固定其它维度,而某个维度的元素全部选取。
例: 有一个三阶张量 Xi,j,k ,其列纤维(column fibers),行纤维(row fibers)和管纤维(tube fibers)如下图所示。
1.3 切片(Slice)
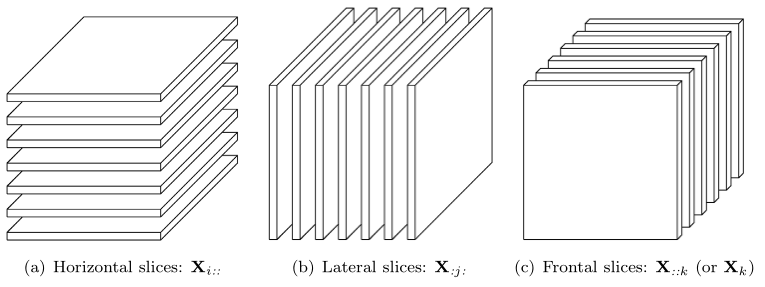
是张量的二维截面,除了两个维度,其他维度全部固定。
例: 有一个三阶张量 Xi,j,k ,其水平切片(horizontal slices),横向切片(lateral slices)和前切片(frontal slices)如下图所示。
1.4 范数(Norm)
一个张量 X∈RI1×I2×⋯×IN 的范数是所有元素的平方和开平方,记为 ∣∣X∣∣。
∣∣X∣∣=i1=1∑I1i2=1∑I2⋯iN=1∑INxi1i2⋯iN2
1.5 内积(Inner product)
对于两个相同维度的张量 X,Y∈RI1×I2×⋯×IN,他们的 内积 表示为对应(相同下标)元素的乘积的和,如下式子:
⟨X,Y⟩=i1=1∑I1i2=1∑I2⋯iN=1∑INxi1i2⋯iNyi1i2⋯iN
可以发现,⟨X,X⟩=∣∣X∣∣2 。
1.6 Rank-one tensors
一种特殊的张量,如果一个 N 阶张量能表示为 N 个一维向量的外积(outer product),那么该张量即为Rank-One Tensor,如下式子:
X=a(1)∘a(2)∘⋯∘a(N)
其中“∘”符号代表外积操作。可以发现张量的每个元素为对应向量元素的乘积,即下式子成立:
xi1i2⋯iN=ai1(1)ai2(2)⋯aiN(N)
1.7 对称性(Symmetry)
当一个张量的所有维度的大小都相同,可以称其为 立方体(cubical)。而当一个立方体的张量的每个元素在其下标的排列中仍保持不变,即可称该张量为 超对称的(supersymmetry) 。
例如,一个三阶张量 X∈RI×I×I 是超对称的当下式成立时满足:
xijk=xikj=xjik=xjki=xkij=xkjii,j,k=1,2,⋯,I
更一般的情况,还存在局部对称,即在某两维或更多维是对称的情况。例如,三阶张量的前切面(frontal slices)是对称的二维矩阵。
1.8 对角张量(Diagonal tensors)
一个张量 X∈RI1×I2×⋯×IN 是对角张量,当且仅当 i1=i2=⋯=iN 时 xi1i2⋯iN=0 。
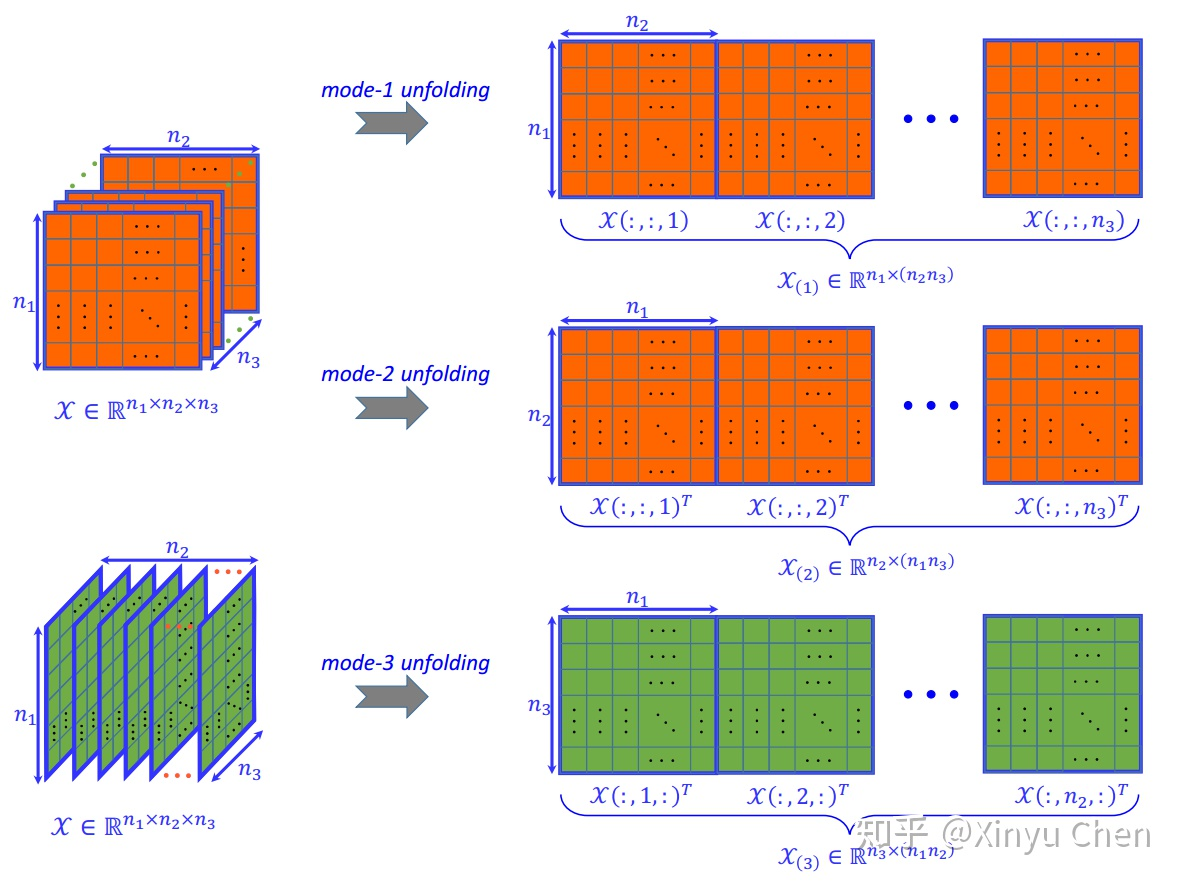
1.9 矩阵化(Matricization)
将高阶张量转化为一个矩阵,在此仅讨论mode-n 矩阵化。
对于三阶张量,有三种展开方式,如下图
1.10 张量乘法(Tensor multiplication)
张量乘矩阵
一个高阶张量 X∈RI1×I2⋯×IN 和一个二阶矩阵 U∈RJ×In 的 n-mode 乘法如下:
(X×nU)i1⋯in−1jin+1⋯iN=in=1∑Inxi1i2⋯iNujin
其他公式:
Y=X×nU⟺Y(n)=UX(n)
X×mA×nB=X×nB×mA(m=n)
X×nA×nB=X×n(BA)
张量乘向量
一个高阶张量 X∈RI1×I2⋯×IN 和一个一维向量 V∈RIn 的 n-mode 乘法如下:
(X×ˉnv)i1⋯in−1in+1⋯iN=in=1∑Inxi1i2⋯iNvin
其他公式:
X ×ˉm a ×ˉn b=(X ×ˉm a) ×ˉn−1 b=(X ×ˉn b) ×ˉm aform<n
上式中间部分,由于 X 与 b 相乘后维度减少一维,在 m<n 的情况下,原来的第 m 维消失,后面维度整体前移一维,所以原来的第 n 维变为了 n−1 维。
1.11 三种矩阵乘法
(1) Kronecker product
对于两个矩阵 A∈RI×J ,B∈RK×L ,其 Kronecker product 表示为 A⊗B ,其结果为 (IK)×(JL) 大小的矩阵:
A⊗B=⎣⎢⎢⎢⎢⎡a11Ba21B⋮aI1Ba12Ba22B⋮aI2B⋯⋯⋱⋯a1JBa2JB⋮aIJB⎦⎥⎥⎥⎥⎤=[a1⊗b1a1⊗b2a1⊗b3⋯aJ⊗bL−1aJ⊗bL]
如下例子:
[1321]⊗[0231]=⎣⎢⎢⎢⎡1⋅01⋅23⋅03⋅21⋅31⋅13⋅33⋅12⋅02⋅21⋅01⋅22⋅32⋅11⋅31⋅1⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡0206319304026231⎦⎥⎥⎥⎤
(2) Khatri-Rao product
对于两个矩阵 A∈RI×K ,B∈RJ×K ,其 Khatri-Rao product 表示为 A⊙B ,其结果为 (IJ)×K 大小的矩阵:
A⊙B=[a1⊗b1a2⊗b2⋯aK⊗bK]
它由两个矩阵对应的列向量的Kronecker积排列而成。因此,Khatri-Rao积又叫做对应列Kronecker积。
注: 若 a,b 是向量,则有 a⊗b=a⊙b 。
(3) Hadamard product
按张量的对应元素相乘,需要两个矩阵的大小相同。对于两个矩阵 A∈RI×J ,B∈RI×J ,其 Hadamard product 表示为 A∗B ,其结果为 I×J 大小的矩阵:
A∗B=⎣⎢⎢⎢⎢⎡a11b11a21b21⋮aI1bI1a12b12a22b22⋮aI2bI2⋯⋯⋱⋯a1Jb1Ja2Jb2J⋮aIJbIJ⎦⎥⎥⎥⎥⎤
二、张量的Tucker分解
Tucker分解是SVD分解的高阶形式,其将张量分解为一个核张量与每一维度上对应矩阵的乘积。具体来说,以三阶张量 X∈RI×J×K 为例,其Tucker分解写为如下形式:
X≈G×1A×2B×3C=p=1∑Pq=1∑Qr=1∑Rgpqr ap∘bq∘cr=[[G;A,B,C]]
其中,A∈RI×P,B∈RJ×Q,C∈RK×R 是不同维度上的因子矩阵,这些矩阵通常被认为是不同维度上的主成分。G∈RP×Q×R 称为核张量,其中的每个元素代表了不同成分之间的交互程度。
从元素的角度看,Tucker分解可以写为:
Xijk≈p=1∑Pq=1∑Qr=1∑Rgpqraipbjqckri=1,⋯,I,j=1,⋯,J,k=1,⋯,K
P,Q和R是因子矩阵 A,B,C 的成分数(例如因子矩阵的列数)。如果 P,Q和R 小于I,J,K,那么张量 G 可以被认为是张量 X 的压缩版本。
2.1 HOSVD算法

2.2 HOOI算法
若 X 是一个大小为 I1×I2×⋯×IN 的 N 阶张量,那么计算 Tucker 分解要解决的优化问题为
min∥∥∥∥X−[[G;A(1),A(2),⋯,A(N)]]∥∥∥∥(1)
其中,G∈RR1×R2×⋯×RN, 矩阵 A(n)∈RIn×Rn 且列正交。
如果在最优解处,那么核张量 G 必然满足
G=X×1(A(1))T×2(A(2))T×3⋯×N(A(N))T(2)
将上式导入到公式(1)中,那么优化目标可以重写为:
∥∥∥∥X−[[G;A(1),A(2),⋯,A(N)]]∥∥∥∥2=∥X∥2−2⟨X,[[G;A(1),A(2),⋯,A(N)]]⟩+∥∥∥∥[[G;A(1),A(2),⋯,A(N)]]∥∥∥∥2=∥X∥2−2⟨X×1(A(1))T×2⋯×N(A(N))T,G⟩+∣∣G∣∣2=∥X∥2−2⟨G,G⟩+∥G∥2=∥X∥2−∥G∥2=∥X∥2−∥∥∥∥X×1(A(1))T×2⋯×N(A(N))T∥∥∥∥2
最小化上述式子,即最大化下式:
A(n)max∥∥∥∥X×1(A(1))T×2⋯×N(A(N))T∥∥∥∥subject toA(n)∈RIn×Rnand columnwise orthogonal






